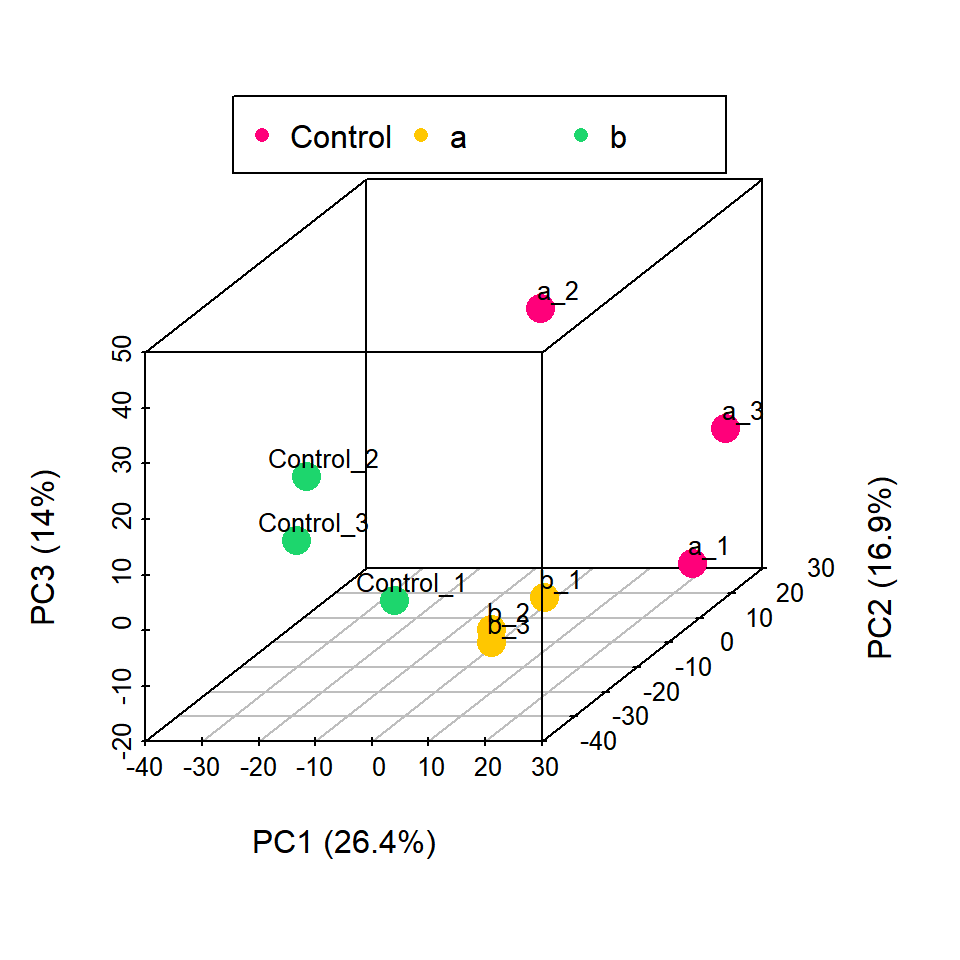
# 代码来源:https://www.r2omics.cn/
# 加载R包,没有安装请先安装 install.packages("包名")
library(scatterplot3d)
# 读取PCA数据文件
df = read.delim("https://www.r2omics.cn/res/demodata/PCA/data.txt",# 这里读取了网络上的demo数据,将此处换成你自己电脑里的文件
header = T, # 指定第一行是列名
row.names = 1 # 指定第一列是行名
)
df=t(df) # 对数据进行转置,如果想对基因分组则不用转置
# 读取样本分组数据文件
dfGroup = read.delim("https://www.r2omics.cn/res/demodata/PCA/sample.class.txt",
header = T,
row.names = 1
)
# PCA计算
pca_result <- prcomp(df,
scale=T # 一个逻辑值,指示在进行分析之前是否应该将变量缩放到具有单位方差
)
pca_result$x<-data.frame(pca_result$x)
# 设置颜色,有几个分组就写几个颜色
colors <- c("#ff007a","#ffc700","#1dd66d")
colors <- colors[as.numeric(as.factor(dfGroup[,1]))]
# 设置点形状,仅供参考
# shape<-16:18
# shape<-shape[as.numeric(as.factor(dfGroup[,1]))]
# 计算PC值,并替换列名,用来替换坐标轴上的标签
pVar <- pca_result$sdev^2/sum(pca_result$sdev^2)
pVar = round(pVar,digits = 3)
colnames(pca_result$x)[1:3] = c(
paste0("PC1 (",as.character(pVar[1] * 100 ),"%)"),
paste0("PC2 (",as.character(pVar[2] * 100 ),"%)"),
paste0("PC3 (",as.character(pVar[3] * 100 ),"%)")
)
# 绘图
s3d <- scatterplot3d(pca_result$x[,1:3],
pch = 16, # 点形状
color=colors, # 点颜色
cex.symbols = 2 # 点大小
)
# 设置图例
legend("top",
legend = unique(dfGroup[,1]),
col = c("#ff007a","#ffc700","#1dd66d"),
pch = 16,
inset = -0.1,
xpd = TRUE,
horiz = TRUE)
# 设置文字标注
text(s3d$xyz.convert(pca_result$x[,c(1,2,3)] + 2),
labels = row.names(pca_result$x),
cex = 0.8,col = "black")